
I can’t get out of my head the instantly infamous paper by Bendavid et al. at Stanford Medical School from a few weeks back, claiming to estimate the prevailing exposure to SARS-Cov-2 in Santa Clara County, California, by antibody tests on a random sample of the population. The study has garnered a lot of attention because of its optimistic outcome: Something between 1.5 and 4 percent of the population were estimated to have been already infected, far more than the official number of cases, which, if true, would imply an infection fatality rate below 0.2%.
The paper has attracted a great deal of criticism, and has already been revised. Much of the critique was targeted at the problematic sampling procedure — which I think is not such a big deal — and the weird ethical lapses. But the gaping hole in the paper is in its treatment of test specificity.
The problem, in a nutshell, is this: 1.5% of the tests they carried out (50 out of 3,330) yielded positive results. In order to estimate the true rate of seropositivity in the population, we need to know approximately how many of those positive test results were correct. They estimate the specificity from their laboratory tests of samples known to be negative (because they were produced before the origin of the virus, or, at least, its entrance into the US), of which 368 out of 371 were indeed negative. (Strangely, the first version of the paper reported 369 out of 371, which is a pretty substantial difference. This figure has not been consistently updated.) This suggests the test specificity is 99.2%, which would make about half the positive results false. But it’s even worse than that, because 3 false results out of 371 might be a randomly low number for a much higher failure rate. The paper recognises this, appealing to the Clopper-Pearson method for computing confidence intervals for binomial probabilities, which yields at a 95% confidence intervals of about (97.6%, 99.9%). If the specificity is anything below 98.5% and they measured 1.5% positives, then the maximum likelihood estimate for the true positive rate is 0. This raises two questions:
- They claim to have taken the specificity into account, saying “We use a bootstrap procedure to estimate confidence bounds for the unweighted and weighted prevalence, while accounting for sampling error and propagating the uncertainty in the sensitivity and specificity.” They produced a 95% CI of (0.7%, 1.8%). What did they think they were doing?
- How should this be analysed?
The bootstrap is a brilliant tool, but since it resamples from the data, or from the fitted model, it tends to miss out on uncertainty from what could have been observed but wasn’t. It’s not clear, though, whether the bootstrap has anything to do with the problem here. The updated version includes an appendix with a calculation from Bayes’ Theorem that the probability of a sampled person being infected is 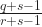
How should the data be analysed? The problem is, Bayes’ Theorem doesn’t play well with frequentist confidence intervals, so it’s easy to end up in a logical muddle if we try to calculate a confidence interval for the true probability of seropositive, given that we’ve observed 1.5% positive. What does it even mean? It would be quite reasonable to say, values of false-positive rate above 1.5% are perfectly plausible, in which case true positive rates down to 0% are plausible, hence there is no justification for claiming evidence for any positive lower bound on the true incidence of seropositivity, and then call it a day.
The “bootstrap” approach that they seem to have made up without much justification is a kind of incoherent mixed-Bayesian-frequentist approach: Inverting the normal approximation to the sampling distribution of the parameters (I think that’s what they mean by the “empirical distribution”) as though it were a posterior, that they then sample from to generate .
Instead, it would be most natural to analyse this in a purely Bayesian framework. You could start off with a uniform prior on the true seropositive rate π and the specificity s. Then the posterior will be proportional to 
The updated version of the paper includes a large number of additional tests on pre-Covid samples, bringing the total to 3324, with just 16 false positives, so again about a 99.5% specificity. If we believe this, we get a much more favourable credible interval — though still not as favourable as reported in the paper — of (0.55%,1.52%). (They report a 95% confidence interval for the unweighted incidence (0.7%, 1.8%).)
Should we believe their new results? I’m not sure. One argument against: They report on 13 different sources of negative samples, but these produce wildly variable specificities. The most extreme is a sample of 150 pre-Covid serum samples that yielded 4 false positives, and on the other side 1102 samples that yielded no false positives — both have substantially less than 1% probability if specificity is 99.5%, but they pull in different directions.
For the aficionados: Actually, there’s also a sensitivity that needs to be considered. In tests of 157 known seropositive samples, only 130 produced positive results. This isn’t as problematic as the specificity — which has the potential for wiping out all of the positive tests — but it will increase our estimates of the true positive rate, while widening the uncertainty. Writing r for the sensitivity (the probability of a positive test given that the individual is seropositive) the posterior likelihood now becomes
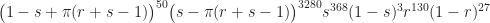
with the original sensitivity data, or
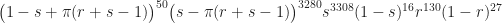
with the updated sensitivity data.
The 95% credible intervals for π (without demographic weighting) are then (.06%,1.7%) with the original sensitivity data, and (0.67%, 1.9%) with the updated sensitivity data. This last is fairly close to the reported results in the revised paper. Unsurprising, since with 3000 instead of 300 samples, the uncertainty in the sensitivity is no longer a major issue.
